

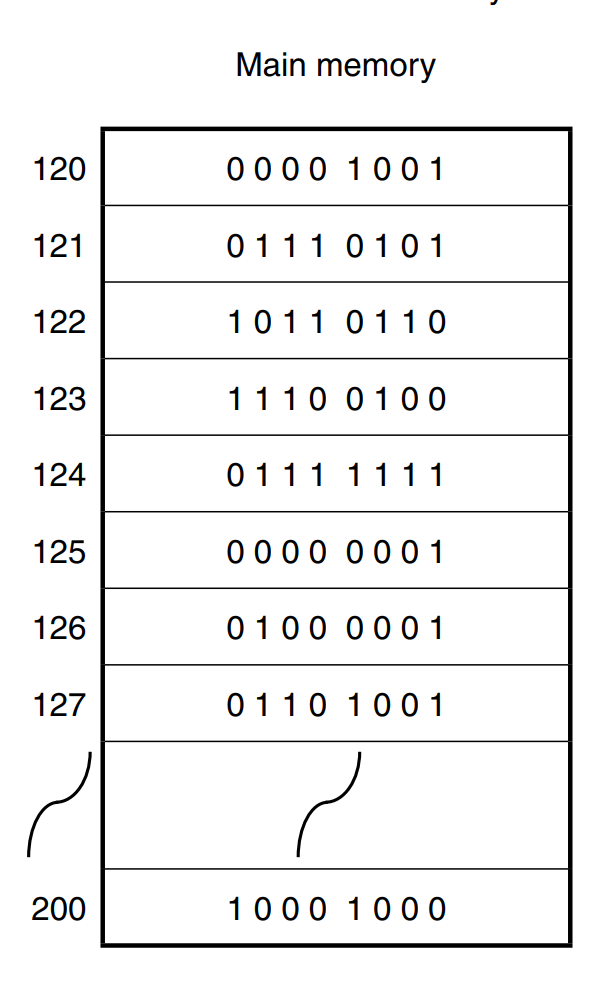
Assembly language and machine code are closely related, representing two levels of programming that allow instructions to be given directly to a computer's CPU. Here’s a breakdown of the relationship:
Definition: Machine code consists of binary code (combinations of 0s and 1s) that is directly executed by the computer's CPU. It’s the most fundamental form of code and specifies exact, low-level instructions that the CPU performs.
Execution: Because machine code is tailored to a specific CPU architecture, it runs very efficiently. However, it’s hard for humans to read or write directly due to its complexity and lack of readability.
Definition: Assembly language is a low-level programming language that uses short, human-readable mnemonics (like ADD for addition, MOV for move) instead of binary numbers. Each instruction in assembly language maps almost directly to an instruction in machine code.
Translation: To execute assembly code, it needs to be converted into machine code through an assembler. This process translates each mnemonic and symbolic representation into the corresponding binary machine code instructions.
Advantages: Assembly language is more readable and writable by humans compared to machine code. Programmers can work closer to the hardware level without needing to manipulate binary directly, which allows more precise control over the CPU.
One-to-One Mapping: In many cases, each assembly instruction corresponds directly to a single machine code instruction. This one-to-one mapping enables precise control over the hardware.
Hardware-Specific: Both assembly language and machine code are designed for a specific CPU architecture. Assembly language instructions are essentially shorthand symbols for the machine code that the particular CPU can understand.
Translation and Execution: While assembly language must be assembled into machine code before a CPU can execute it, the instructions produced are identical to what would be written in machine code. This makes assembly an essential bridge between high-level coding and direct hardware interaction.
Level Noob Explanation
Imagine you’re organizing a large event, like a wedding with seating arrangements. The planning process resembles how a two-pass assembler works, with each pass fulfilling a specific purpose before the final event.
Reading Through Guest Information: First, you go through all the guests' RSVPs, checking who is attending and who isn’t. In this phase, you're not assigning seats yet; you’re simply making a list of guests and what they’ll need (like any special accommodations or dietary restrictions).
Building the Guest List (Symbol Table): As you review the RSVPs, you compile a list of all confirmed guests along with details like their relationship to the couple, group preferences, or any specific instructions
Defining the Table Layout (Address Assignment): You also start mapping out the tables in the event space, noting where each table will be. At this stage, you don’t assign guests to tables; you just know there are, for example, 10 tables, and you’ve noted the general layout.
Checking for Missing Info: As you review RSVPs, you might notice some guests haven't clarified if they’re attending or any food preferences. You mark these for follow-up, similar to flagging undefined symbols in Pass 1.
Purpose of Pass 1: You now have a complete list of guests and tables set up, but you haven’t assigned anyone to a specific seat. This prepares everything so you can easily seat guests in the second phase.
Looking Up Guest Information: With your complete guest list from Pass 1, you begin assigning each guest to a specific seat. You use the list to place people according to their group preferences or table assignments, ensuring the seating layout respects everyone’s needs and relationships
Assigning Tables and Seats (Translation): You start translating guest relationships and group dynamics into actual table placements. For example, if you know “ADD” is a close family member, they’ll be seated at the family table.
Final Details and Problem-Solving: As you seat guests, you make final adjustments, ensuring everyone is placed correctly. If someone is unexpectedly absent or if a name on your list doesn’t show up, you resolve it then—similar to error-checking in Pass 2.
Final Seating Chart: By the end of this pass, you have a finalized seating chart where each guest has a designated spot, and all requirements are met. You’re ready for the event with a fully completed plan.
Purpose of Pass 2: This pass finalizes the seating chart, ensuring all guests (labels) are placed correctly. Every guest has a designated table, with all issues resolved and ready for execution.
Pass 1: Gather guest names, group preferences, and table layout without assigning specific seats—equivalent to creating a symbol table and assigning memory locations.
Pass 2: Use the completed guest list to assign specific seats, finalizing details and resolving issues to prepare for the event—similar to translating assembly language to machine code.

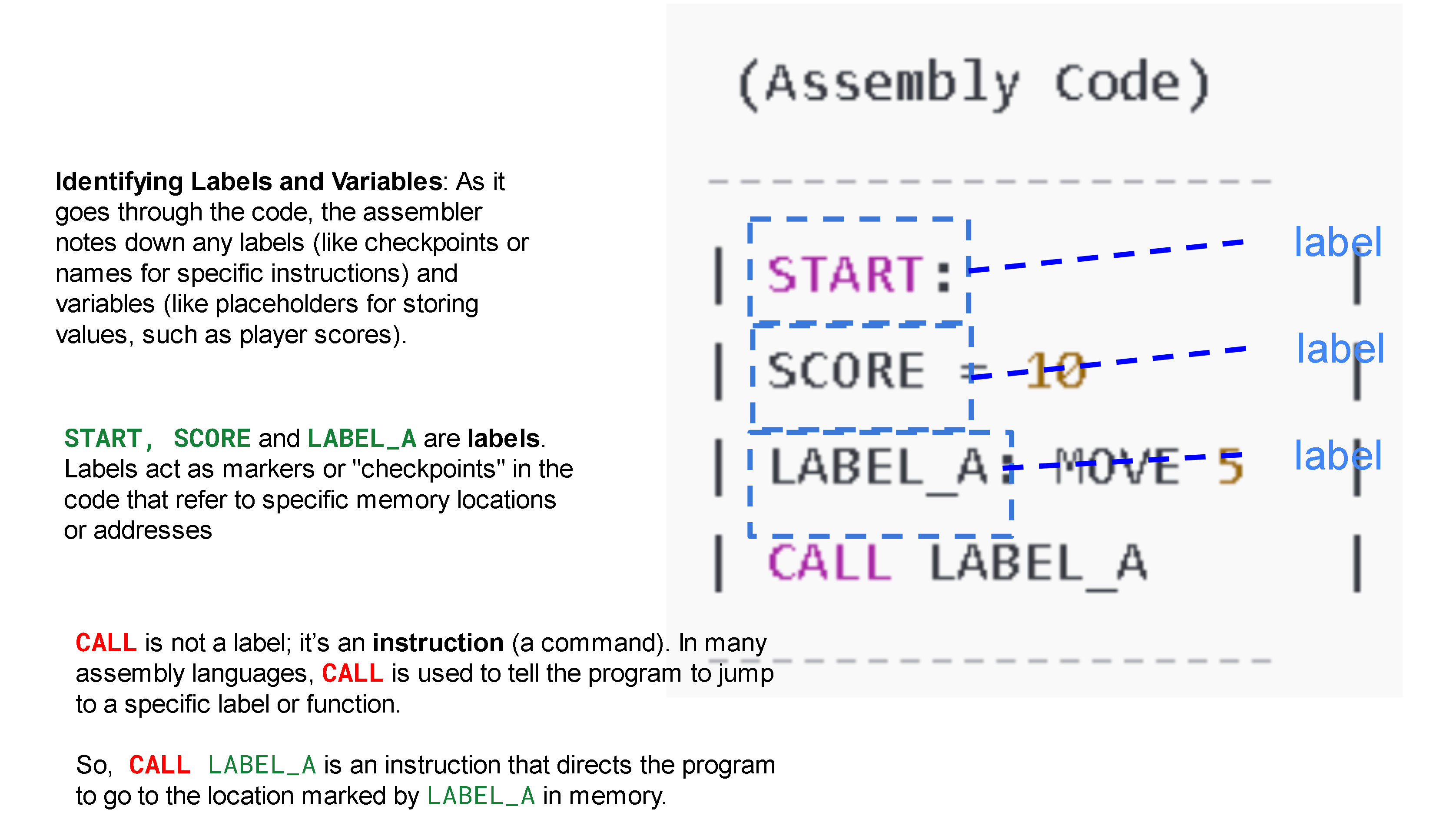


Lexical Analysis: The assembler reads each line of the assembly code, identifying and parsing labels, mnemonics (like ADD, MOV), operands, and comments. It ignores comments and other non-instructional data.
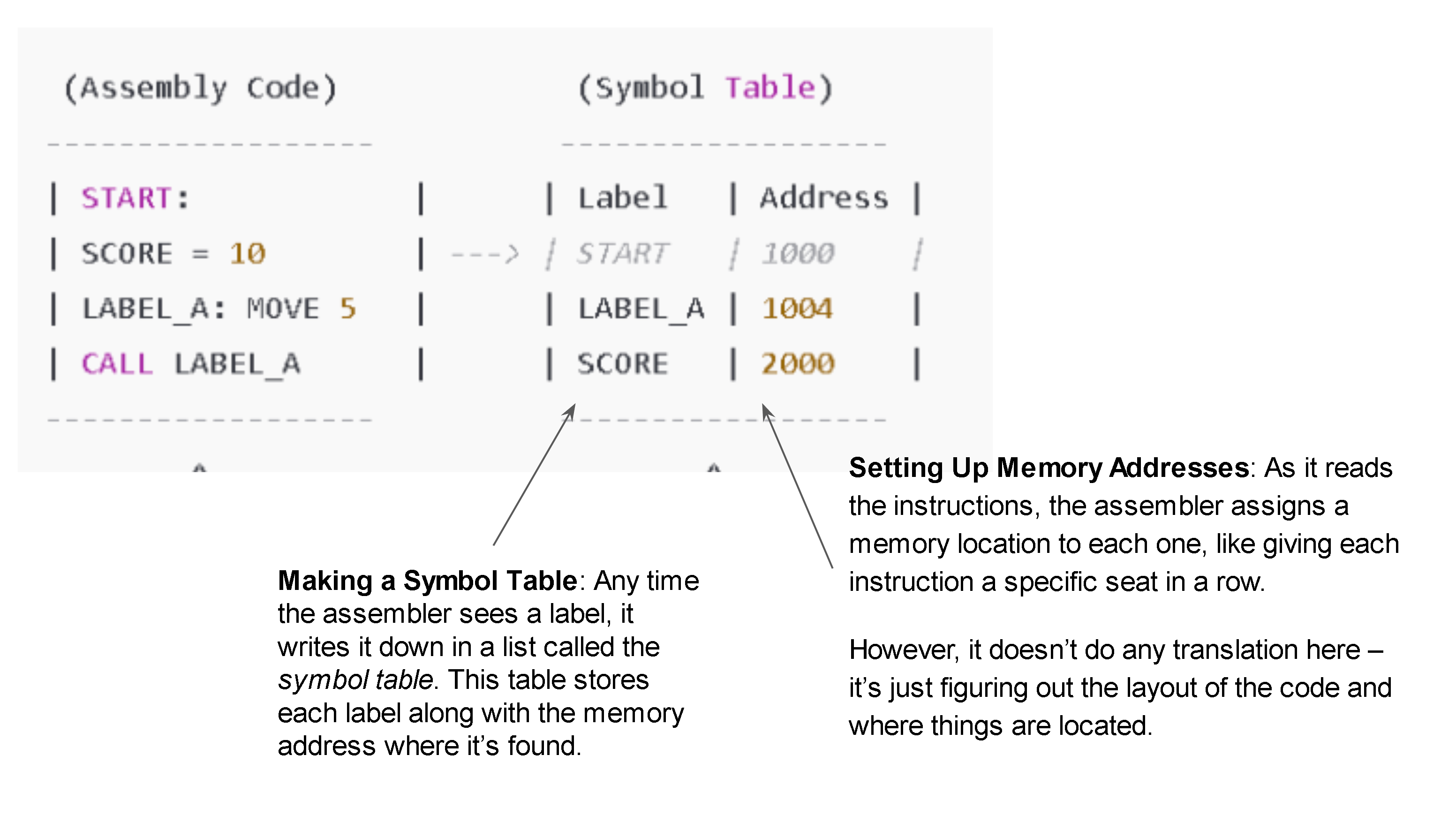
Symbol Table Construction: The assembler identifies labels (symbols) in the code, which often represent memory addresses or locations in the program. Each label is stored in a symbol table alongside its memory address. Labels might refer to variables, instructions, or locations in the code, and are essential for tracking where instructions and data reside.
Address Assignment: As the assembler reads through each instruction, it assigns memory addresses to them sequentially. It tracks the memory locations of instructions and data, calculating the addresses each label should point to. This phase defines memory locations but does not yet translate the code into machine instructions.
Error Checking: Any errors related to undefined symbols (e.g., if a label is used but never defined) are usually flagged in this pass. Syntax errors, however, may only be partially caught, as a detailed analysis happens in Pass 2.
Purpose of Pass 1: This pass ensures that all symbols have memory addresses assigned and builds the symbol table, which is essential for resolving references in the code during the next pass.
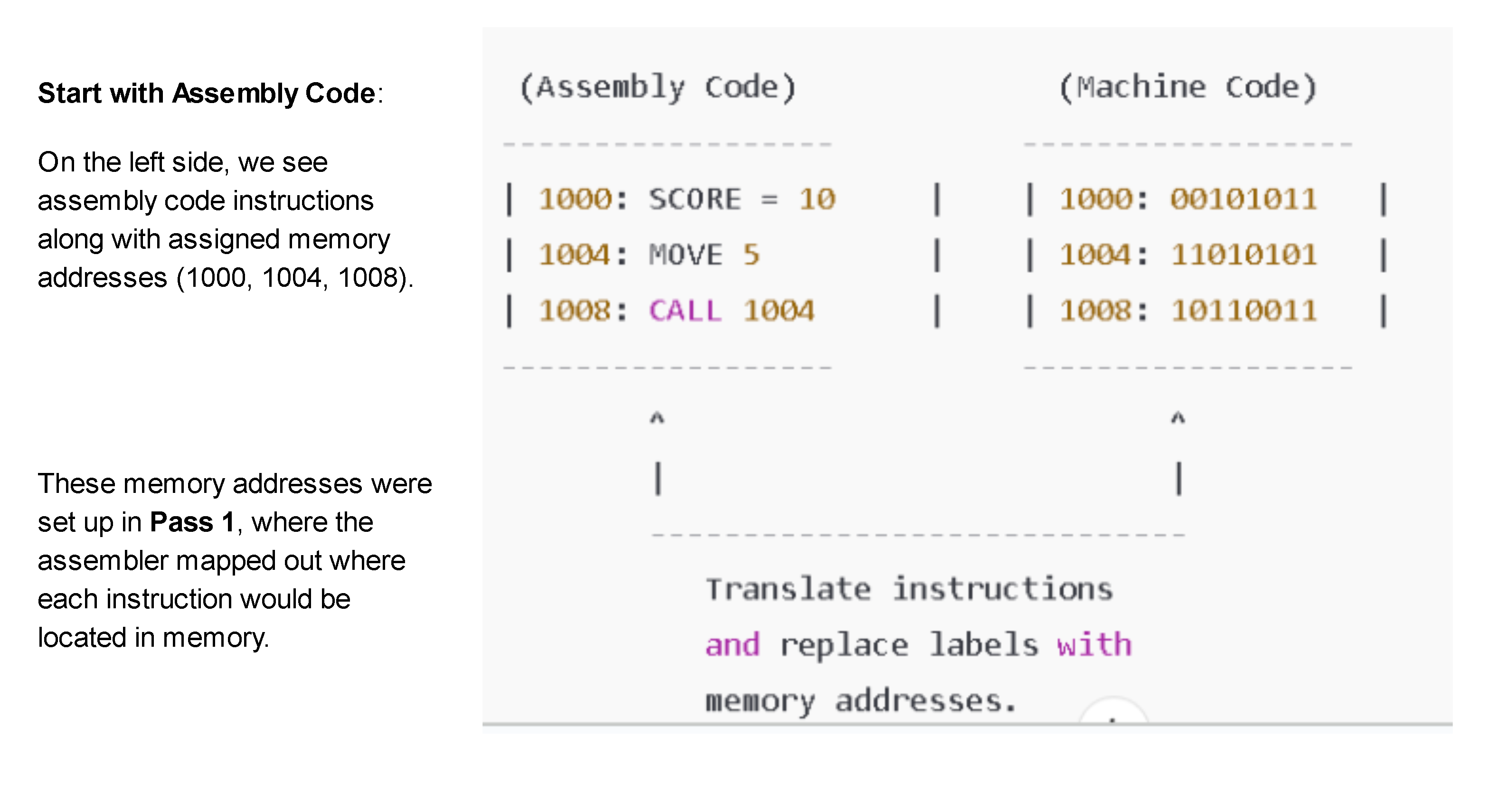
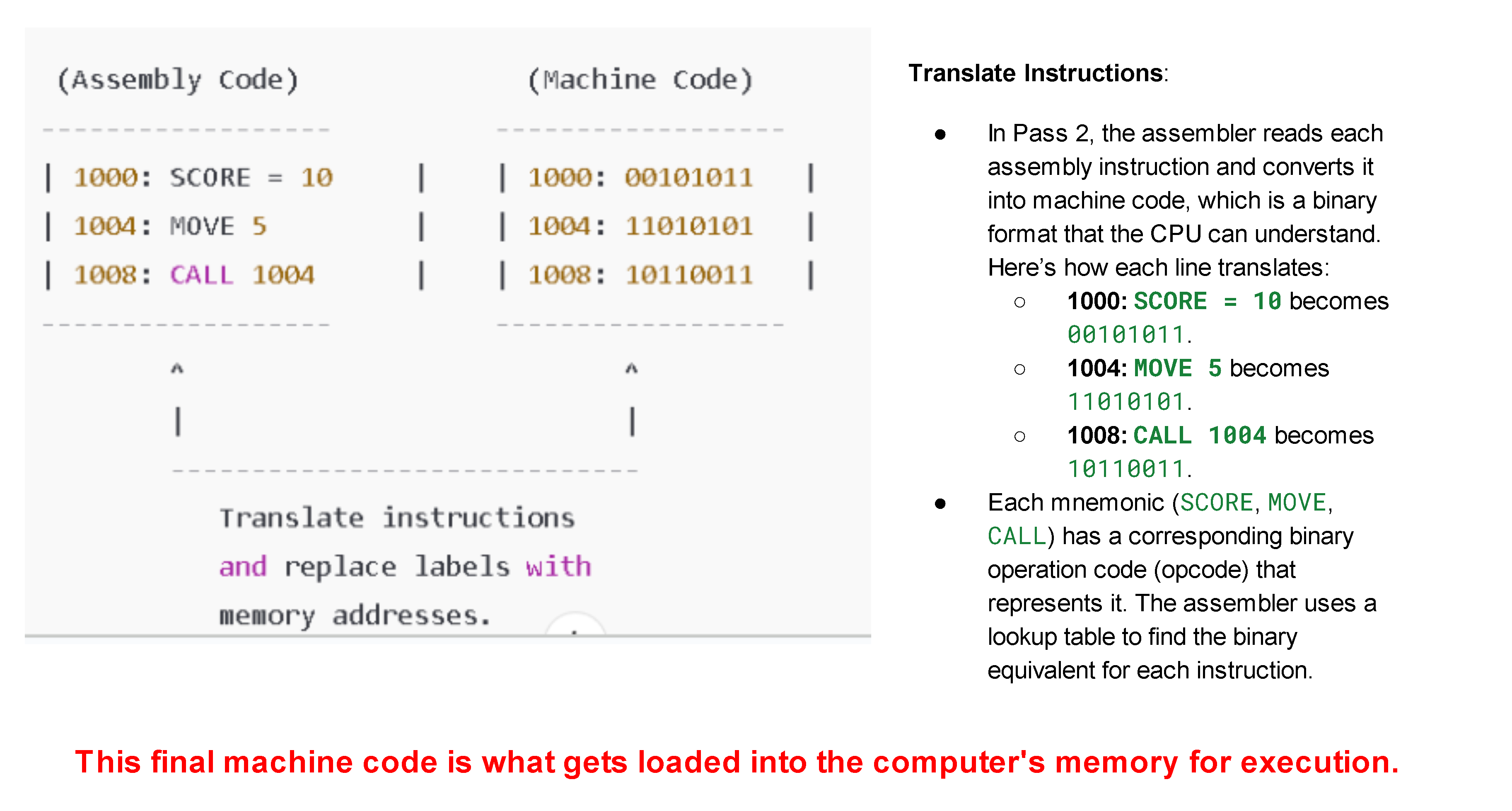
Symbol Table Lookup: Using the symbol table created in Pass 1, the assembler revisits each instruction in the assembly code. It replaces symbolic labels with the actual memory addresses they represent, as defined in the symbol table.
Mnemonic Translation: Each assembly language instruction mnemonic (like ADD, SUB, etc.) is translated into its corresponding machine code operation, typically represented in binary or hexadecimal. This is often done by looking up each mnemonic in an operation code (opcode) table, which lists each mnemonic with its binary opcode.
Addressing Mode Resolution: For instructions that involve addressing modes (e.g., immediate, direct, indirect), the assembler determines the correct machine code format for the instruction based on how data or memory is being accessed.
Binary Code Generation: The assembler generates the final machine code, a series of binary instructions ready for execution by the CPU. It resolves any symbolic references by inserting the corresponding addresses, ensuring all labels and instructions are correctly represented in machine language.
Error Checking: The assembler performs additional checks for errors, including incorrect operand types, invalid instructions, and unresolved symbols, flagging any issues missed in Pass 1.
Purpose of Pass 2: This pass completes the translation of assembly language into machine code by using the information from Pass 1 to produce fully assembled and executable machine code.
What does an assembler do?
Machine code consists of which type of instructions?
What is a key benefit of assembly language?
What's the relationship between machine code and assembly language?
How is machine code defined in computing?
Which characteristic defines assembly language in programming?
How is assembly language executed by the CPU?
Who natively executes machine code instructions with optimal efficiency?






