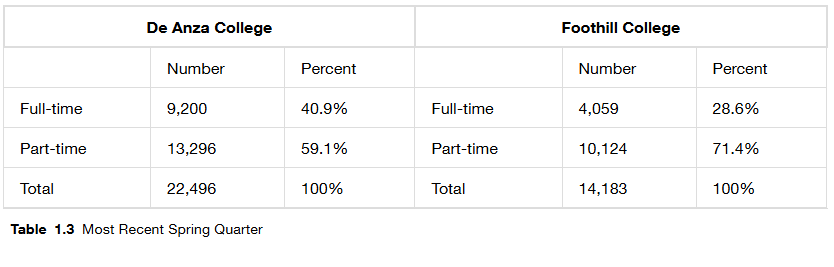
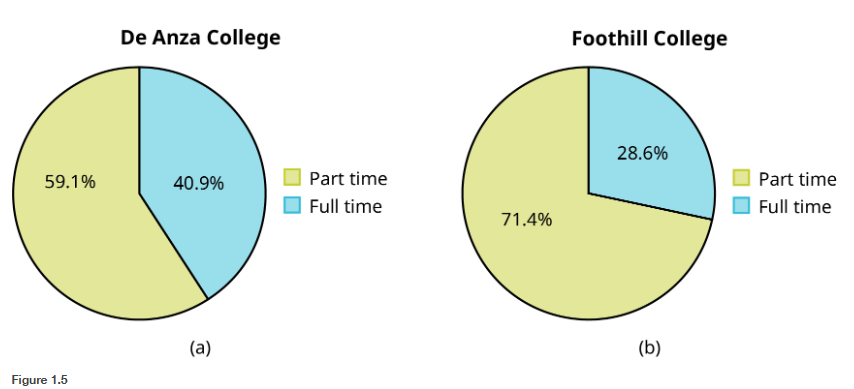
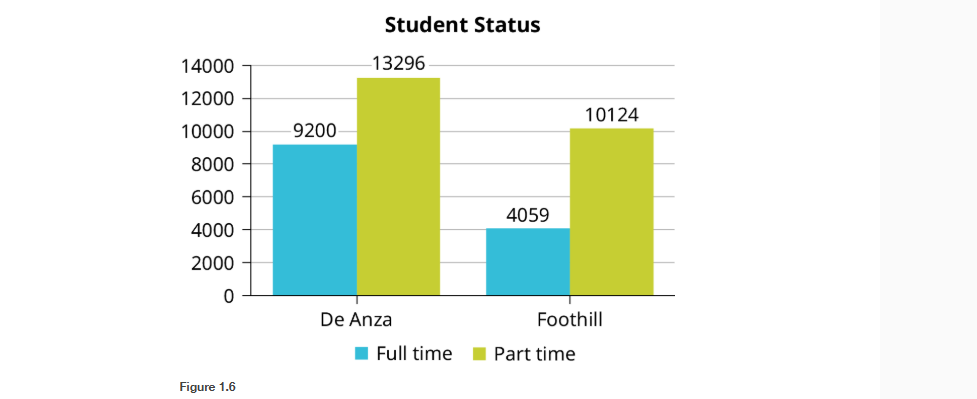
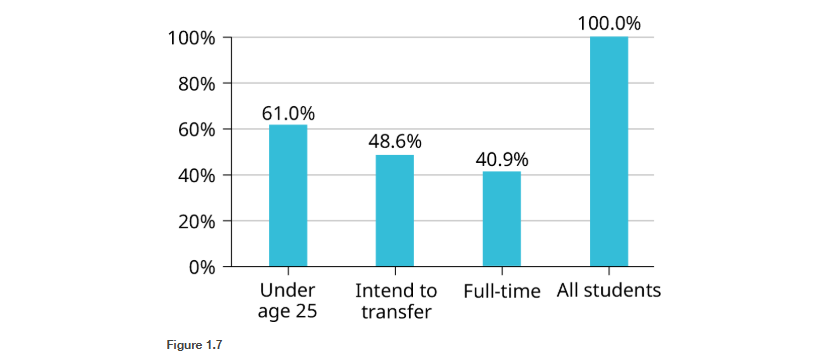
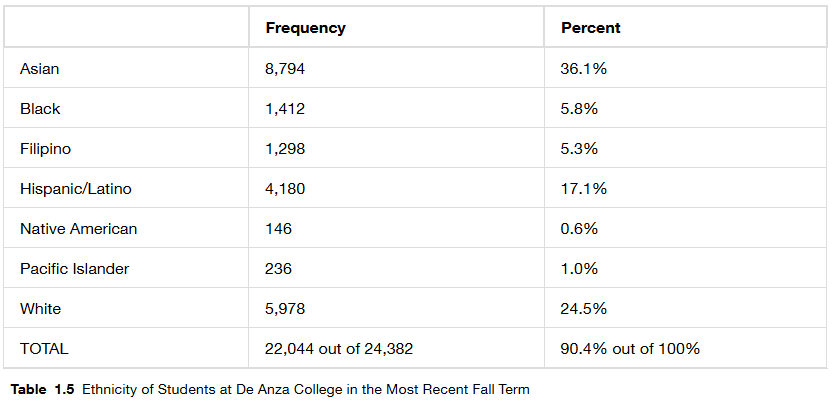
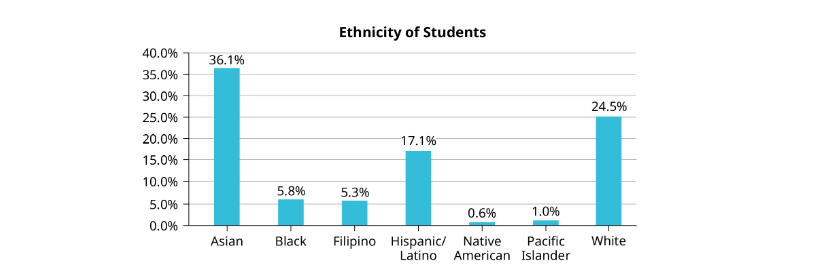
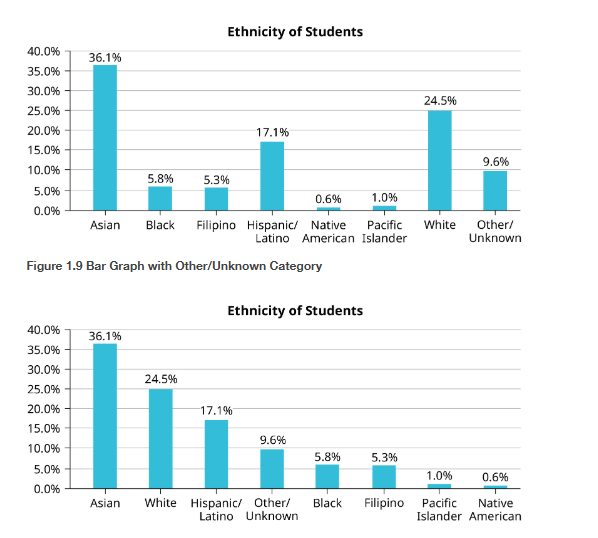
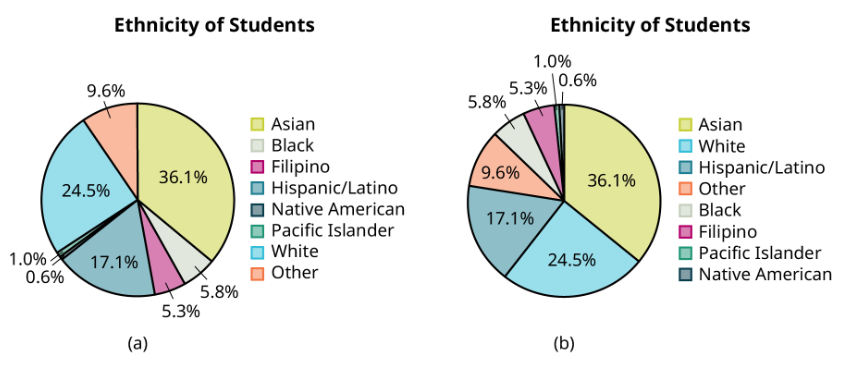
Based on those previous definitions, determine which of these are qualitative, quantitative continuous or discrete data
a. The number of pairs of shoes you own
b. The type of car you drive
c. The distance it is from your home to the nearest grocery store
d. The number of classes you take per school year
e. The type of calculator you use
f. Weights of dogs at an animal shelter
g. Number of correct answers on a quiz
h .A statistics professor collects information about the classification of her students as first-year students, sophomores, juniors, or seniors.

i. The registrar at State University keeps records of the number of credit hours students complete each semester. The data collected are summarized in the histogram. The class boundaries are 10 to less than 13, 13 to less than 16, 16 to less than 19, 19 to less than 22, and 22 to less than 25.